-
네거티브 샘플링을 이용한 Word2Vec 구현(w. TensorFlow)Archive/통계&코딩이것저것 2021. 11. 16. 17:14
Word2Vec 모형은 상대적으로 간단한 모형이지만, skipgram으로 모든 임베딩 벡터를 업데이트 할 시에 너무 무거운 모델이 되는 단점이 있다. 이에 몇 단어들만 샘플링해서 더 가볍게(!) 구현한 것이 '네거티브 샘플링을 이용한 Word2Vec' 이다.
미리 다음 페이지들을 참조했음을 말해둔다. 코드는 텐서플로우 공식 홈페이지, 한글 전처리는 anseunghwan님의 깃허브를 참고했다.
https://www.tensorflow.org/tutorials/text/word2vec?hl=en
Word2Vec | TensorFlow Core
ML 커뮤니티 데이를 놓쳤습니까? 수요에 대한 모든 세션 시계 보기 세션을 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English Word2Vec Word2Vec은 단일 알고리즘이 아니라 대규모 데
www.tensorflow.org
04) 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS)
이번 챕터에서는 네거티브 샘플링(Negative Sampling)을 사용하는 Word2Vec을 직접 케라스(Keras)를 통해 구현해봅시다. ##**1. 네거티브 샘플링( ...
wikidocs.net
https://an-seunghwan.github.io/nlp/%EC%A0%84%EC%B2%98%EB%A6%AC-workflow/
전처리 workflow
품사 기반 전처리의 overview
an-seunghwan.github.io
먼저 설명!
Word2Vec에는 Cbow 방법과 Skip-Gram 방법이 있다. 이 중에서, 여기서는 Skip-Gram 방법을 사용하도록 하겠다.
Skip-gram and Negative Sampling

pos tagging ,명사 추출을 마쳤다고 하자. 속도 이슈로 Mecab을 쓴다.   여기에서 만약 target word가 마케팅이라고 하면, window size가 1일 때 context words 는 데마코, ROI 가 된다.

에러는 무시하자 스킵 그램 모델의 학습 목적! 은 target word가 주어졌을 때 context word를 예측할 확률을 최대화 하는 것이다. 이는 어떻게 어떻게 수식으로 표현될 수 있는데.... 이는 패스하도록 하겠다. 저 위에 1번째 링크에 들어가면 찾을수 있다!! ㅎㅎ
여기서 '예측할 확률'이라 함은 target word의 임베딩 벡터와, context word의 임베딩 벡터를 내적하고(내적 값이 클수록 유사하다는 뜻) 이 값을 '소프트맥스 함수'에 통과시켜 확률 값으로 만든 것을 말한다.

소프트 맥스 함수는 이렇게 생겼다 (대충..) 모든 target word와 context word에 대해서 곱한 것을 분모로 쓰게 되는데, 이는 큰 데이터셋의 경우 엄청난 계산량을 요구하게 된다. 이때 네거티브 샘플링을 통해 아예 상관없는 단어 몇 개를 뽑아서 이진 분류 문제로 바꾸게 되면, 훨씬 계산량을 단순화할수 있다.
네거티브 샘플링은 무엇일까? 만약 '쿼터'가 target word라고 했을 때, 전체 단어 집합에서 context word가 아닌 단어를 n개 뽑아서 샘플로 만든다.

그리고 context word의 집합과 negative sample을 라벨링한 후 concat 한다.

예시(돼지는 뺌) 그리고 훈련 데이터의 단어 집합의 크기만큼의 임베딩 레이어를 두개 준비한다!
각 임베딩 테이블에 초기값으로 아무거나 값을 집어넣는다.
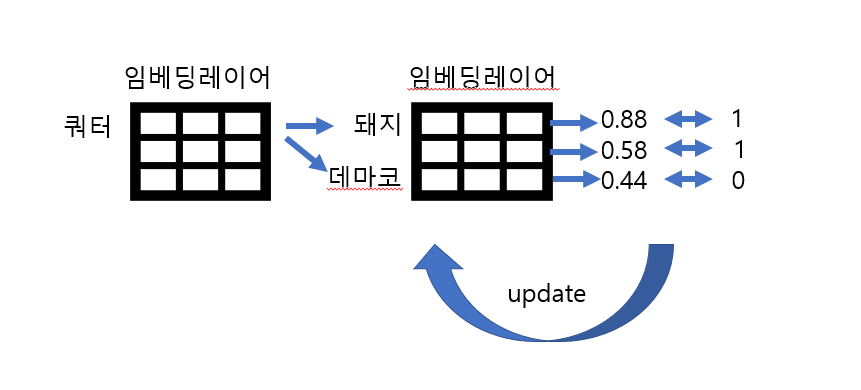
중심 단어와 주변 단어의 내적값을 예측값으로 하고, label과의 오차를 최소화하는 방향으로 임베딩 벡터값을 업데이트한다. 이후에는 두개의 임베딩 테이블 중 아무거나 최종 임베딩 테이블로 사용할 수 있다.
check point:
1. 포스태깅 과정에서, Mecab이 Okt 보다 백만배 정도 더 빠르다. 그런데 40만 건 이상부터 현저히 느려지기 시작해서 서버가 killed 되는 바람에... 50낱말 이상 되는 원문은 제외하고 약 25만 건만 돌렸더니 굉장히 빠름.
2. 두번째 고비.(아직도 해결을 못 함) tf에서 학습하면서 업데이트 하는 과정이 너무 느리다. 20시간은 걸리는 듯. (솔직히 느린지 모르겠는데 쿼터가 이정도로 느리면 못 올린다고 함) tf를 gpu로 어떻게 올릴까? 어렵다고 한다.
21-11-17 수정
3. 단어 수를 32,000개( 빈도수 6이상 ) 로 한정하고, 문장의 길이도 너무 길거나 짧지 않은 걸로 11만 개로 제한하여 다시 돌려보았다. 단어 수가 너무 많은 게 함정이었던 것 같다. EDA의 중요성을 다시 한번 느낌. (사실 이번에도 EDA를 그렇게 잘 한건 아님) 튜닝만 좀 더 하면 더 잘 될 것 같다. 학습시간 총 약 3시간.

'하나님'을 넣었는데, 뭔가 잘 나오는것 같애 'Archive > 통계&코딩이것저것' 카테고리의 다른 글
[Back to the Basic]엔트로피 (0) 2021.11.26 [Back to the Basic] 검정 (0) 2021.11.25 Ordinal Regression (0) 2021.10.13 Neural Collaborative Filtering 논문 리뷰 (0) 2021.09.14 기업명 표준화(클리닝) (0) 2021.09.06