-
[HandsOn]13. 텐서플로에서 데이터 적재와 전처리하기 - 내용 정리1[도서완독]Hands On Machine Learning 2022. 7. 26. 19:38
공부하려고 앉았다가 1시간을 웹서핑했다😂 정신차리자!
다른 말인데 유기견, 유기묘 사진을 요즘 보고 있는데 너무 귀엽고 불쌍하다...
사정만 된다면 한 마리 데려와서 키우고 싶은데 사실 내가 1인 가구이기도 하고 집도 돈도 없으니...(주륵) 모두에게 못할짓..
나중에 경제적으로 주거적으로 안정적이 된다면 꼭 친구 한마리를 데려와서 같이 살고 싶다!
메모리 용량에 맞지 않는 아주 큰 규모의 데이터셋으로 딥러닝 시스템을 훈련해야 한다면?
대용량 데이터는 정규화처럼 데이터 전처리가 필요한데 인코딩을 해야 한다면?-> 사용자 정의 전처리 층을 만들거나, 케라스에서 제공하는 표준 전처리 층을 사용하면 됨
13.1 데이터 API
메모리에서 전체 데이터셋을 생성해볼수 있음.
이렇게 10개의 원소가 있는 텐서를 받아서, 데이터셋을 만든다.
다음과 같이 데이터셋의 아이템을 순회할 수 있음.
X=tf.range(10) dataset=tf.data.Dataset.from_tensor_slices(X) dataset for item in dataset: print(item)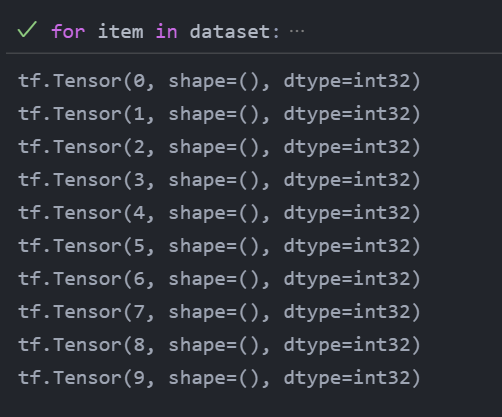
13.1.1 연쇄 변환
dataset=dataset.repeat(3).batch(7) for item in dataset: print(item)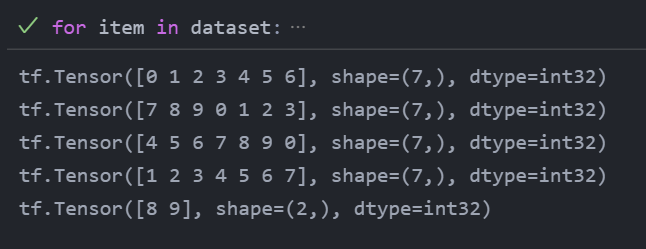
기존의 데이터셋을 3번 반복한 후에, 이 데이터셋을 7개씩 그룹으로 묶는다.
가장 마지막 배치는 2인데, drop_remainder=True 로 호출하면 마지막 배치를 버리고 동일한 크기로 맞춤.
map()메서드를 호출하여 아이템을 변환할 수도 있음.
모든 아이템에 2를 곱하여 새로운 데이터셋을 만듬.
dataset=dataset.map(lambda x: x*2)이 함수는 데이터에 원하는 어떤 전처리 작업에도 적용할 수 있는데, 이따금 이미지 크기 변환이나 회전 같은 복잡한 계산을 포함하기 때문에 여러 스레드로 나누어 속도를 높이는 것이 좋다. num_parallel_calls 매개변수를 지정하면 간단함. map()메서드에 전달하는 함수는 텐서플로 함수로 변환 가능해야 한다.(무슨 소리일까...)
map 메서드가 각 아이템에 변환 적용 but apply()메서드는 데이터셋 전체에 변환을 적용.
filter(), take() 메서드도 있다.
13.1.2 데이터 셔플링
경사 하강법은 훈련 세트에 있는 샘플이 iid 할때 최고의 성능을 발휘. shuffle()메서드를 사용하여 샘플을 섞는 방법이 제일 간단쓰....
dataset=tf.data.Dataset.range(10).repeat(3) dataset=dataset.shuffle(buffer_size=5,seed=42).batch(7) for item in dataset: print(item)여튼 실제 데이터로 보자.
캘리포니아 주택 데이터셋을 여러 개의 CSV로 나누기
캘리포니아 주택 데이터셋을 적재하고, 섞은 다음 훈련, 검증, 테스트 세트로 나누었다고 가정하자.
from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler housing = fetch_california_housing() X_train_full, X_test, y_train_full, y_test = train_test_split( housing.data, housing.target.reshape(-1, 1), random_state=42) X_train, X_valid, y_train, y_valid = train_test_split( X_train_full, y_train_full, random_state=42) scaler = StandardScaler() scaler.fit(X_train) X_mean = scaler.mean_ X_std = scaler.scale_메모리에 맞지 않는 매우 큰 데이터셋인 경우 일반적으로 먼저 여러 개의 파일로 나누고 텐서플로에서 이 파일들을 병렬로 읽게 함.주택 데이터셋을 20개의 CSV 파일로 나누어 보자.
def save_to_multiple_csv_files(data, name_prefix='train', header=None, n_parts=10): housing_dir = os.path.join("datasets", "housing") os.makedirs(housing_dir, exist_ok=True) path_format = os.path.join(housing_dir, "my_{}_{:02d}.csv") filepaths = [] m = len(data) for file_idx, row_indices in enumerate(np.array_split(np.arange(m), n_parts)): print(file_idx) print(row_indices) part_csv = path_format.format(name_prefix, file_idx) filepaths.append(part_csv) with open(part_csv, "wt", encoding="utf-8") as f: if header is not None: f.write(header) f.write("\n") for row_idx in row_indices: f.write(",".join([repr(col) for col in data[row_idx]])) f.write("\n") return filepaths만든 디렉토리 안에 n_parts 개의 분할된 데이터가 쌓이게 된다.
train_data = np.c_[X_train, y_train] valid_data = np.c_[X_valid, y_valid] test_data = np.c_[X_test, y_test] header_cols = housing.feature_names + ["MedianHouseValue"] header = ",".join(header_cols) #%% train_filepaths = save_to_multiple_csv_files(train_data, "train", header, n_parts=20) valid_filepaths = save_to_multiple_csv_files(valid_data, "valid", header, n_parts=10) test_filepaths = save_to_multiple_csv_files(test_data, "test", header, n_parts=10) import pandas as pd pd.read_csv(train_filepaths[0]).head()
입력 파이프라인 만들기
파일 경로가 담긴 데이터셋을 만들자.
filepath_dataset=tf.data.Dataset.list_files(train_filepaths,seed=42)list_files() 함수는 파일 경로를 섞은 데이터셋을 반환한다고 함!
n_readers = 5 dataset = filepath_dataset.interleave( lambda filepath: tf.data.TextLineDataset(filepath).skip(1), cycle_length=n_readers) for line in dataset.take(5): print(line.numpy())그 다음 인터리브 메소드를 호출하여 한 번에 다섯 개의 파일을 한 줄씩 번갈아 읽는다.
솔직히 이해가 안됐다... 그치만 거의 안 쓰인다고 한다.
그리고 어쨌든 간단히 설명하면
train data를 n개로 나누고-> 섞어서-> 또 섞는다... 는 개념인 것 같다.
(이렇게까지 해야하니...?)
이 부분은 패스하도록 하겠음.
13.1.5 프리페치
prefetch 를 호출하면, 훈련 알고리즘이 한 배치로 작업을 하는 동안 이 데이터셋이 동시에 다음 배치를 준비.
훨씬 짧은 시간에 훈련을 할 수 있음.
'[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn]13. 텐서플로에서 데이터 적재와 전처리하기 - 연습문제 (0) 2022.07.29 [HandsOn]13. 텐서플로에서 데이터 적재와 전처리하기 - 내용 정리2 (0) 2022.07.29 [HandsOn]12. 텐서플로를 사용한 사용자 정의 모델과 훈련 - 연습문제 풀이 (0) 2022.07.21 [HandsOn]12. 텐서플로를 사용한 사용자 정의 모델과 훈련 - 내용 정리 2 (0) 2022.07.20 [HandsOn]12. 텐서플로를 사용한 사용자 정의 모델과 훈련 - 내용 정리 1 (0) 2022.07.19