-
[HandsOn] 17. 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습- 내용 정리1[도서완독]Hands On Machine Learning 2022. 8. 23. 20:33
ㅠㅠ 요즘 너무 힘들다... 집에 가고 싶은데 회사에 남아서 공부 중😥
그래도 ... 공부해야 하니까 힘내자!
회사에 나만 남았다고 한다....
오토인코더: 레이블되지 않은 훈련 데이터를 사용해도 입력 데이터의 밀집 표현을 학습할 수 있는 인공 신경망
일부 오토인코더는 훈련 데이터와 매우 비슷한 새로운 데이터를 생성할 수 있는데, 이를 생성 모델이라고 함.
예를 들어, 얼굴 사진으로 오토인코더를 훈련하면 이 모델은 새로운 얼굴을 생성할 수 있게 됨. 하지만 흐릿하고 실제 이미지 같지는 않다.
하지만 생성적 적대 신경망(GAN) 으로 생성한 얼굴은 이를 가짜라고 믿기 힘들 정도라고 함!
https://thispersondoesnotexist.com/
This Person Does Not Exist
thispersondoesnotexist.com
새로 고침을 할 때 마다 얼굴이 바뀌는데, 존재하지 않는 사람이라고 함...!
- 초해상도(이미지 해상도 높이기)
- 이미지를 컬러로 바꾸기
- 강력한 이미지 편집(원하지 않는 배경 바꾸기)
- 간단한 스케치를 실제 같은 이미지로 바꾸기
- 동영상에서 다음 프레임 예측하기
- 데이터 증식
- (텍스트, 오디오, 시계열 같은) 여러 다른 종류의 데이터 생성
- 다른 모델의 취약점을 식별하고 개선하기
GAN은 이런 것들에 널리 사용된다고 한다... 신기....
오토인코더와 GAN은 모두 비지도 학습이며, 둘 다 밀집 표현을 학습하고 생성 모델로 사용할 수 있음.
비슷하지만, 작동 방식은 크게 다름
오토인코더부터 시작해보자!
17.1 효율적인 데이터 표현
다음과 같은 숫자 시퀀스를 쉽게 기억할 수 있는 방법이 있을까?
40,27,25,36,81,59,54,78,64,55
50,48,46,44,42,40,38,36,34,32,30,28,26,24,22,20,18,16,14
첫번째 시퀀스가 짧아서 더 쉬워보이지만, 두번째 시퀀스를 자세히 보면 짝수만 나열했다는 걸 알 수 있고, 이런 패턴을 알고 나면 두번째를 외우기가 더 쉬움.
패턴을 찾으면 효율적으로 정보를 저장할 수 있음.
오토인코더는 입력을 받아 효율적인 내부 표현으로 바꾸고, 입력과 가장 가까운 어떤 것을 출력.
오토인코더는 입력을 내부 표현으로 바꾸는 인코더(또는 인지 네트워크)와 내부 표현을 출력으로 바꾸는 디코더 (또는 생성 네트워크) 로 구성됨

출력층의 뉴런 수가 입력 개수와 동일하다는 것을 제외하면, 오토 인코더는 일반적으로 MLP와 구조가 동일.
그림에서는 뉴런 두개로 구성된 하나의 은닉층(인코더)이 있음. 그리고 뉴런 3개로 구성된 출력층(디코더) 이 있음.
오토인코더가 입력을 재구성하기 때문에 출력을 종종 재구성이라고 부르고, 비용함수는 재구성이 입력과 다를 때 모델에 벌점을 부과하는 재구성 손실을 포함.
내부의 표현이 입력 데이터보다 저차원이기 때문에(ex. 3차원 대신 2차원) 이런 오토인코더를 과소완전(undercomplete)이라고 함.
그렇기 때문에 입력을 코딩(부호)로 간단히 복사할 수 없으며, 입력과 똑같은 걸 출력하기 위한 다른 방법을 찾아야 하는데, 이는 입력 데이터에서 가장 중요한 특성을 학습하고, 중요하지 않은 건 버리게 만듬.
차원 축소를 위한 아주 간단한 과소완전 오토인코더를 어떻게 구현하는지 보자.
17.2. 과소완전 선형 오토인코더로 PCA 수행하기
오토인코더가 선형 활성화 함수만 사용하고, 비용 함수가 평균제곱오차(MSE)라면 , 이는 결국 주성분 분석(PCA)를 수행하는 것으로 볼 수 있음.
np.random.seed(42) tf.random.set_seed(42) encoder = keras.models.Sequential([keras.layers.Dense(2, input_shape=[3])]) decoder = keras.models.Sequential([keras.layers.Dense(3, input_shape=[2])]) autoencoder = keras.models.Sequential([encoder, decoder]) autoencoder.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1.5))다음 코드로 3D 데이터셋에 PCA를 적용해 2D에 투영하는 간단한 선형 오토인코더를 만듬.
MLP와 많이 다르지 않지만,
- 인코더와 디코더 두개의 원소로 구성하는데, 두 개 다 하나의 Dense 층을 가진 일반적인 시퀀셜 모델임.
케라스 모델은 다른 모델의 층으로 사용할 수 있다는 걸 기억! - 오토인코더의 출력 개수가 입력 개수와 동일
- 단순한 PCA를 수행하기 위해서는 활성화 함수를 사용하지 않으며(모든 뉴런이 선형) , 비용 함수는 MSE
history = autoencoder.fit(X_train, X_train, epochs=20) codings = encoder.predict(X_train)동일한 X_train이 입력과 타깃에 사용됨!
(오토인코더는 데이터에 있는 분산이 가능한 많이 보존되도록 데이터를 투영할 최상의 2D 평면을 찾음)
원본 데이터셋-> 오토인코더의 은닉 층 출력
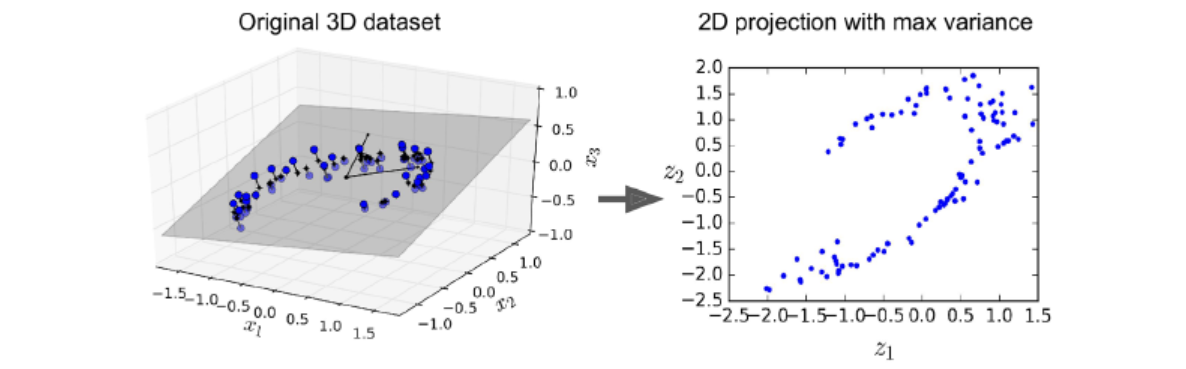
오토인코더를 자기 지도 학습의 한 형태로 볼수 있다. (즉, 자동으로 생성한 레이블에서 지도 학습 기법을 사용)
이 경우는 단순히 입력과 같음.17.3 적층 오토인코더
오토인코더도 은닉층을 여러 개 가질 수 있음. 이를 적층 오토인코더, 또는 심층 오터인코더 라고 함
층을 더 추가하면 오토인코더가 더 복잡한 코딩을 학습할 수 있지만, 너무 강력해진다면?
오토 인코더는 훈련 데이터를 완벽하게 재구성하겠지만 이 과정에서 유용한 데이터 표현을 학습하지 못할 것임.
그리고 새로운 샘플에 잘 일반화될 것 같지도 않다.
적층 오토인코더의 구조는 전형적으로 가운데 은닉층을 기준으로 대칭.
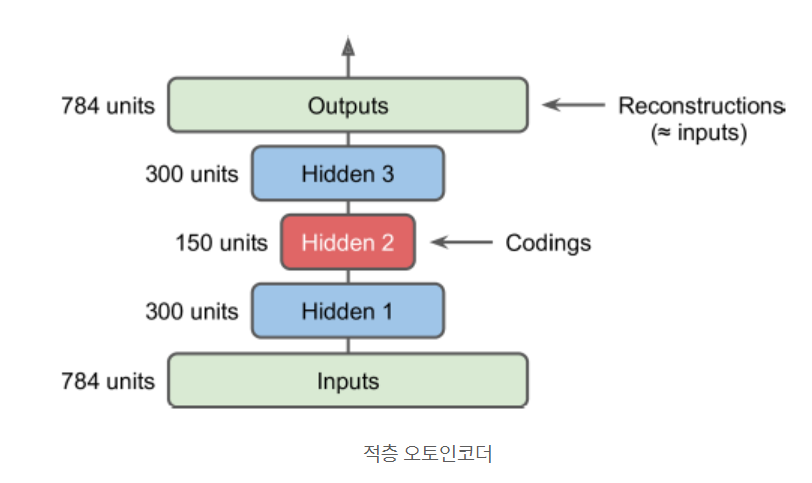
17.3.1 케라스를 사용하여 적층 오토인코더 구현하기
(10장의 데이터 적재 방법을 통해 적재하고 정규화한) 패션 MNIST 데이터셋에서 SELU 활성화 함수를 사용해 적층 오토인코더를 만들어 보자.
stacked_encoder = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.Dense(100, activation="selu"), keras.layers.Dense(30, activation="selu"), ]) stacked_decoder = keras.models.Sequential([ keras.layers.Dense(100, activation="selu", input_shape=[30]), keras.layers.Dense(28 * 28, activation="sigmoid"), keras.layers.Reshape([28, 28]) ]) stacked_ae = keras.models.Sequential([stacked_encoder, stacked_decoder]) stacked_ae.compile(loss="binary_crossentropy", optimizer=keras.optimizers.SGD(learning_rate=1.5), metrics=[rounded_accuracy]) history = stacked_ae.fit(X_train, X_train, epochs=20, validation_data=(X_valid, X_valid))- 앞에서처럼, 오토인코더 모델을 인코더와 디코더 두 개 서브 모델로 나눔
- 인코더는 28X28 흑백 이미지를 받고, 펼침. 각 입력 이미지에 대해 인코더는 크기가 30인 벡터를 출력
- 디코더는 크기가 30인 코딩을 받아서, Dense 층 두 개에 통과시키고 최종 벡터를 28X28 배열로 변경
- 적층 오토인코더를 컴파일할 때 이진 크로스 엔트로피 손실을 적용. 재구성 작업을 다중 레이블 이진 분류 문제로 다룸. 각 픽셀의 강도는 픽셀이 검정일 확률을 나타냄.
(회귀 문제가 아니라) 이런 식으로 문제를 정의하면 모델이 더 빠르게 수렴하는 경향 - X_train 을 입력과 타깃으로 사용해 모델을 훈련
17.3.2 재구성 시각화
오토인코더가 적절히 훈련되었는지 확인하는 한 가지 방법은 입력과 출력을 비교하는 것.
차이가 너무 크지 않아야 함. 검증 세트에서 원본 이미지 몇 개를 재구성된 것과 함께 그려보자.

원본 이미지(위), 재구성 이미지(아래) 정보를 많이 잃었음. 모델을 더 오래 훈련하거나 인코더와 디코더 층을 늘리거나 코딩의 크기를 늘려야 할수도 있음. 하지만 네트워크가 너무 강력하면 데이터에서 유익한 패턴을 학습하지 못하고 완벽한 재구성 이미지를 만들 것임. 일단은 이 모델을 사용하자.
17.3.3 패션 MNIST 데이터셋 시각화
오토인코더의 장점은 샘플과 특성이 많은 대용량 데이터셋을 다룰 수 있다는 점.
따라서 오토인코더를 사용해 적절한 수준으로 차원을 축소한 후 다른 차원 축소 알고리즘을 사용해 시각화하는 것도 전략.
이 방식으로 패션 MNIST 데이터셋을 시각화해 보자.
먼저 적층 오토인코더의 인코더 모델을 사용해 차원을 30으로 줄임. 그 다음 t-SNE 알고리즘을 구현한 사이킷런 클래스로 시각화를 위해 차원을 2까지 줄임.
from sklearn.manifold import TSNE X_valid_compressed = stacked_encoder.predict(X_valid) tsne = TSNE() X_valid_2D = tsne.fit_transform(X_valid_compressed)plt.scatter(X_valid_2D[:, 0], X_valid_2D[:, 1], c=y_valid, s=10, cmap="tab10")
# https://scikit-learn.org/stable/auto_examples/manifold/plot_lle_digits.html 참고 t-SNE 알고리즘이 식별한 클러스터가 클래스와 잘 매칭된다고함... 그런가? 흠...
이렇게 오토인코더를 차원 축소에 사용할 수 있음.
17.3.4 적층 오토인코더를 사용한 비지도 사전훈련
레이블링이 많이 되지 않은 데이터를 이용한 복잡한 지도 학습 문제를 다루어야 한다면, 비슷한 문제를 학습한 신경망을 찾아 하위층을 재사용하는 것도 한 방법임.
비슷하게 대부분 레이블되지 않은 대량의 데이터셋이 있다면 먼저 전체 데이터(레이블o+레이블x)를 사용해 적층 오토인코더를 훈련함.
그 다음 오토인코더의 하위층을 재사용해 실제 문제를 해결하기 위한 신경망을 만들고 레이블된 데이터를 사용해 훈련할 수 있음.
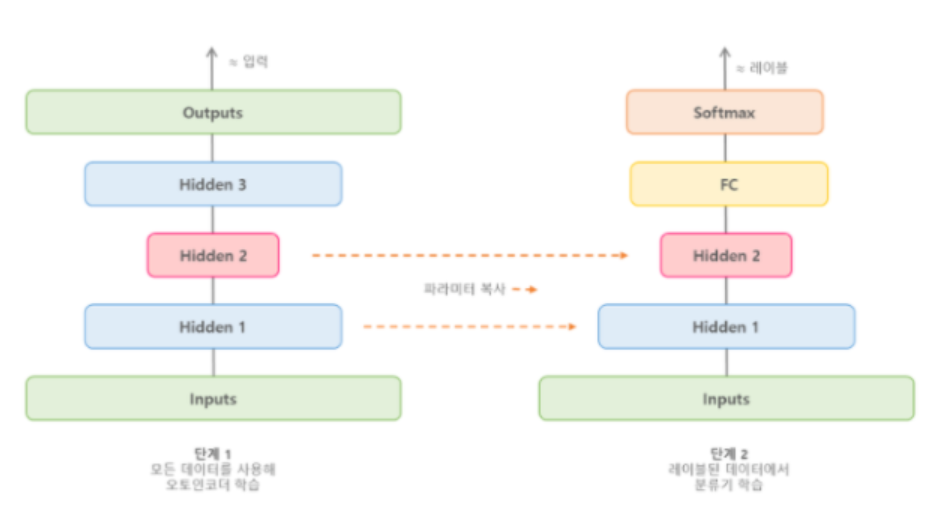
https://ssung-22.tistory.com/60 '[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn] 18. 강화 학습- 내용 정리1 (1) 2022.09.19 [HandsOn] 17. 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습- 내용 정리2 (0) 2022.08.26 [HandsOn] 16. RNN과 어텐션을 사용한 자연어 처리 - 내용 정리3 (0) 2022.08.19 [HandsOn] 16. RNN과 어텐션을 사용한 자연어 처리 - 내용 정리2 (0) 2022.08.18 [HandsOn] 16. RNN과 어텐션을 사용한 자연어 처리 - 내용 정리1 (0) 2022.08.16