-
[HandsOn]15. RNN과 CNN을 사용해 시퀀스 처리하기 - 내용 정리2[도서완독]Hands On Machine Learning 2022. 8. 13. 10:22
15.4 긴 시퀀스 다루기
굉장히 긴 시퀀스로 RNN을 훈련하려면, 펼친 RNN이 매우 긴 네트워크가 됨.
그레이디언트 소실과 폭주 문제가 있을 수 있고, 훈련에 긴 시간이 걸리거나 훈련이 불안정할 수 있음.
또한 입력의 첫 부분을 조금씩 잊어버릴 것임.
15.4.1 불안정한 그레이디언트 문제와 싸우기
전에 배웠던 것처럼, 해당 문제를 완화하기 위한 방법을 RNN에서도 사용할 수 있음.
- 가중치 초기화
- 드롭아웃 등...
수렴하지 않는 Relu(Leaky Relu 등..) 은 도움이 되지 않음!
사실 더 RNN이 불안정해짐... 왜?
만약 출력을 증가시키는 방향으로 가중치가 업데이트 된다면?
타임 스텝마다 출력이 증가-> 결국은 출력이 폭주하게 됨.
수렴하지 않는 활성화 함수는 이를 막지 못하므로, RNN에는 디폴트로 하이퍼볼릭 탄젠트가 사용됨!
배치 정규화는?
RNN에서 효율적으로 사용할 수 없음.
- 층 정규화(Layer Normalization)
배치 정규화와 매우 비슷, but 타임 스텝마다 정규화함
입력과 은닉 상태의 선형조합 직후에 사용됨!
어떻게 구현할 수 있을까?
from tensorflow.keras.layers import LayerNormalization class LNSimpleRNNCell(keras.layers.Layer): def __init__(self, units, activation="tanh", **kwargs): super().__init__(**kwargs) self.state_size = units self.output_size = units self.simple_rnn_cell = keras.layers.SimpleRNNCell(units, activation=None) self.layer_norm = LayerNormalization() self.activation = keras.activations.get(activation) def call(self, inputs, states): outputs, new_states = self.simple_rnn_cell(inputs, states) norm_outputs = self.activation(self.layer_norm(outputs)) return norm_outputs, [norm_outputs]전에 배운 것처럼 keras.layers.Layer를 상속받는다!
생성자에서는 필요한 변수를 정의함.
call() 메서드는 굉장히 직관적임. simple_rnn_cell에서 인풋과 hidden state를 받아서, rnn층에 통과시켜 새로운 아웃풋과 state를 만듬(이때 활성화 함수엔 통과 안시키고 선형 조합만 함!)
(simple rnn에서 output=new state)
그 다음 층 정규화를 하고, 활성화 함수에 통과시킴.
정규화된 output 은 두번 반환되어서 하나는 출력, 하나는 은닉 상태가 됨.
model = keras.models.Sequential([ keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True, input_shape=[None, 1]), keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True), keras.layers.TimeDistributed(keras.layers.Dense(10)) ])이런 식으로 쓰면 됨.
드롭 아웃은 케라스에서 dropout 매개변수나 recurrent_dropout 매개변수를 지원함.
15.4.2 단기 기억 문제 해결하기
RNN을 거치면서 데이터가 변환되므로 일부 정보는 훈련 스텝 후 사라지고, 어느 정도 시간이 지나면 RNN의 상태는 첫번째 입력의 흔적을 가지고 있지 않음.
이런 문제를 해결하기 위해 장기 메모리를 가진 여러 종류의 셀이 연구됨.
LSTM 셀
model = keras.models.Sequential([ keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]), keras.layers.LSTM(20, return_sequences=True), keras.layers.TimeDistributed(keras.layers.Dense(10)) ])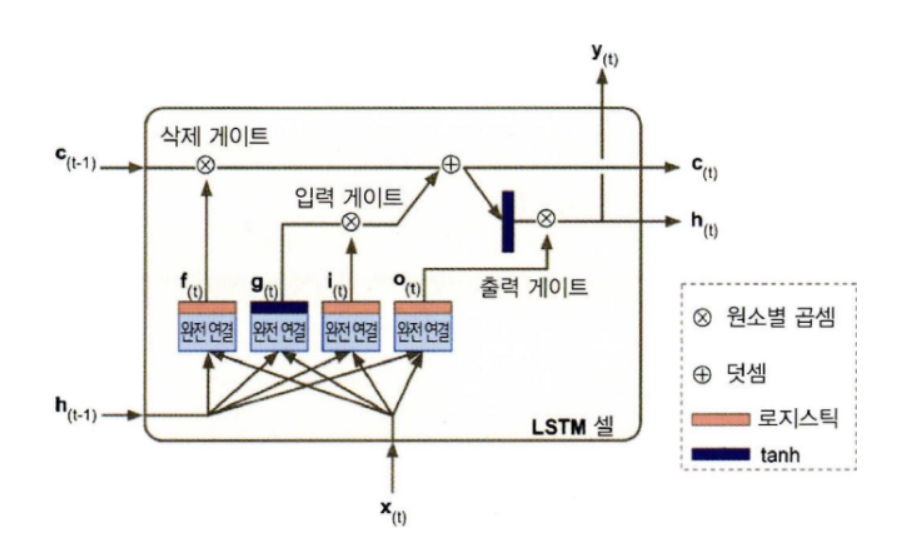
rnn과 달리 state가 두개로 나뉨. c: 장기 상태, h: 장기 상태
- 핵심 아이디어: 네트워크가 장기 상태에 저장할 것, 버릴 것, 읽어들일 것을 학습하는 것!
c부터 보자.
네트워크를 왼->오로 관통하면서, 삭제 게이트를 지나 일부 기억을 잃고, 덧셈 연산으로 새로운 기억( 입력 게이트에서 선택한 기억 추가)을 추가
그리고 바로 출력으로 보내짐.
또한 이 상태는 복사되어 tanh로 전달되고, 출력 게이트에서 걸러진 후 단기상태 h가 됨. (=y)
새로운 기억이 들어오는 곳과 게이트가 어떻게 작동할까?
x와 h 가 4개의 다른 완전 연결 층에 주입.
- 주 층은 g를 출력하는 층: 여기서는 x와 h를 분석 , 장기 상태에 가장 중요한 부분이 저장되고 , 나머지는 버림
- 세 개의 다른 층은 게이트 제어기: 로지스틱 활성화 함수 사용->0~1 출력
0을 출력하면 게이트를 닫고, 1을 출력하면 게이트를 염 - 삭제 게이트: 장기 상태의 어느 부분이 삭제되어야 하는지 제어
- 입력 게이트: g의 어느 부분이 장기 상태에 더해져야 하는지 제어
- 출력 게이트: 장기 상태의 어느 부분을 읽어서 h와 y로 출력해야 하는지 제어
GRU 셀
성능 저하를 최소로 유지하면서 LSTM을 단순화한 모델,
두 개의 상태벡터 c(t), h(t)를 사용하는 대신 h(t) 하나만 사용하여 기억을 누적한다.
- 두 상태 벡터가 하나의 벡터 h로 합쳐짐
- 하나의 게이트 제어기 z가 삭제 게이트와 입력 게이트를 모두 제어
게이트 제어기가 1을 출력하면 삭제게이트 열림, 입력게이트 닫힘
LSTM과 GRU는 매우 성공적이지만, 매우 제한적인 단기 기억을 가지고, 100 step 이상의 시퀀스에서는 학습에 어려움이 있음.
-> 1D 합성곱 층을 사용해 입력 시퀀스를 짧게 줄이자 (?)
1D 합성곱 층을 사용해 시퀀스 처리하기
model = keras.models.Sequential([ keras.layers.Conv1D(filters=20, kernel_size=4, strides=2, padding="valid", input_shape=[None, 1]), keras.layers.GRU(20, return_sequences=True), keras.layers.GRU(20, return_sequences=True), keras.layers.TimeDistributed(keras.layers.Dense(10)) ])'[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn] 16. RNN과 어텐션을 사용한 자연어 처리 - 내용 정리2 (0) 2022.08.18 [HandsOn] 16. RNN과 어텐션을 사용한 자연어 처리 - 내용 정리1 (0) 2022.08.16 [HandsOn]15. RNN과 CNN을 사용해 시퀀스 처리하기 - 내용 정리1 (0) 2022.08.08 [HandsOn]14. 합성곱 신경망을 사용한 컴퓨터 비전 - 내용 정리1 (0) 2022.08.01 [HandsOn]13. 텐서플로에서 데이터 적재와 전처리하기 - 연습문제 (0) 2022.07.29