-
[HandsOn]11.심층 신경망 훈련하기- 연습문제[도서완독]Hands On Machine Learning 2022. 1. 19. 18:06
'핸즈온 완독'프로젝트 2탄!
https://book.naver.com/bookdb/book_detail.nhn?bid=16328592
핸즈온 머신러닝
머신러닝 전문가로 이끄는 최고의 실전 지침서 텐서플로 2.0을 반영한 풀컬러 개정판 『핸즈온 머신러닝』은 지능형 시스템을 구축하려면 반드시 알아야 할 머신러닝, 딥러닝 분야 핵심 개념과
book.naver.com
11장은 MLP에서 좀 더 심층으로 갔을 때 속도나 성능을 향상시키는 방법을 다루고 있다.
문제를 풀면서 내가 이해한 것들, 모르는 것들을 기록하려고 한다.
정답 코드는 여기에!
https://github.com/rickiepark/handson-ml2/blob/master/11_training_deep_neural_networks.ipynb
GitHub - rickiepark/handson-ml2: 핸즈온 머신러닝 2/E의 주피터 노트북
핸즈온 머신러닝 2/E의 주피터 노트북. Contribute to rickiepark/handson-ml2 development by creating an account on GitHub.
github.com
8. CIFAR10 이미지 데이터셋에 심층 신경망을 훈련해보세요.
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu
a. 100개의 뉴런을 가진 은닉층 20개로 심층 신경망을 만들어보세요.
He 초기화와 ELU 활성화 함수를 사용하세요.from keras.datasets import cifar10 import matplotlib.pyplot as plt import numpy as np import tensorflow as tf import math import keras (X_train_full, y_train_full), (X_test, y_test) = cifar10.load_data() X_train = X_train_full[5000:] y_train = y_train_full[5000:] X_valid = X_train_full[:5000] y_valid = y_train_full[:5000] model=keras.models.Sequential() model.add(keras.layers.Flatten(input_shape=[32,32,3])) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal')) model.add(keras.layers.Dense(100,activation='elu',kernel_initializer='he_normal'))ㅋㅋㅋ 무식하게 썼는데 앞으론 for문쓸거임.... 여튼 여기선 elu와 he_normal에 대해 간단하게 설명하겠음!
훈련 중에 생길 수 있는 문제로 "그라디언트 소실" 과 "그라디언트 폭주" 가 있음. https://wikidocs.net/61375
06) 기울기 소실(Gradient Vanishing)과 폭주(Exploding)
깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 점차적으로 작아지는 현상이 발생할 수 있습니다. 입력층에 가까운 층들에서 가중 ...
wikidocs.net
깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 점차적으로 작아지는 현상이 발생할 수 있습니다. 입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 결국 최적의 모델을 찾을 수 없게 됩니다. 이를 기울기 소실(Gradient Vanishing) 이라고 합니다.
반대의 경우도 있습니다. 기울기가 점차 커지더니 가중치들이 비정상적으로 큰 값이 되면서 결국 발산되기도 합니다. 이를 기울기 폭주(Gradient Exploding) 라고 하며, 다음 챕터에서 배울 순환 신경망(Recurrent Neural Network, RNN)에서 쉽게 발생할 수 있습니다.
내가 이해한 것: ftn(WX+b)...를 중첩시키는 과정에서(주로 lstm, rnn) weight를 증가시키면 W>1일때 효과는 W^a배가 된다! 그러므로 조금만 weight를 증가시켜도 엄청나게 증폭되는 것.-> 그라디언트 폭주
쉽게 생각하면 반대로 하는 것-> 그라디언트 소실
기울기 소실을 완화하는 가장 간단한 방법은 은닉층의 활성화 함수로 시그모이드나 하이퍼볼릭탄젠트 함수 대신에 ReLU나 ReLU의 변형 함수를 쓰는 것!
- 시그모이드, 하이퍼볼릭 탄젠트는 입력값이 커질수록 그라디언트가 0에 가까워짐->
역전파 과정에서 전파 시킬 기울기가 점차 사라져서 입력층 방향으로 갈 수록 제대로 역전파가 되지 않는 기울기 소실 문제가 발생할 수 있다고 함.)
여기서 elu란?
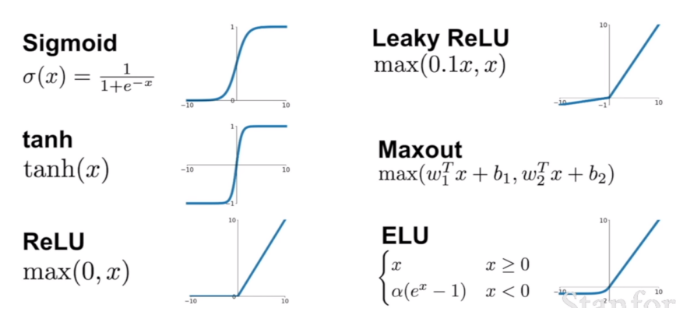
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339 relu의 변종이며, 장단점이 있음. (그라디언트 소실 문제 완화, 죽은 뉴런 만들지 않음 but relu보다 느림)
-
또한, 같은 모델을 훈련시키더라도 가중치가 초기에 어떤 값을 가졌느냐에 따라서 모델의 훈련 결과가 달라지기도 함. 다시 말해 가중치 초기화만 적절히 해줘도 기울기 소실 문제과 같은 문제를 완화시킬 수 있다고 한다.
relu혹은 relu의 변종들 에 대한 초기화 전략중 하나를 He 초기화 라고 부르는데, 2/ 층의 입력개수(fan in) 를 정규분포의 분산으로 하여 무작위로 초기화 한 것을 He 초기화 라고 하는 것 같다.
더 알아야 할까? 정말 모르겠다.
좀 알아본 결과 초기화의 경우 깊은 신경망일때는 써서 효과를 낼 수도 있는데 많이는 안쓰인다구 한다...
b문제: Nadam 옵티마이저와 조기 종료를 사용하여 CIFAR10 데이터셋에 이 네트워크를 훈련하세요. keras.datasets.cifar10.load_ data()를 사용하여 데이터를 적재할 수 있습니다.# 이 데이터셋은 10개의 클래스와 32×32 크기의 컬러 이미지 60,000개로 구성됩니다(50,000개는 훈련, 10,000개는 테스트).# 따라서 10개의 뉴런과 소프트맥스 활성화 함수를 사용하는 출력층이 필요합니다.# 모델 구조와 하이퍼파라미터를 바꿀 때마다 적절한 학습률을 찾아야 한다는 것을 기억하세요.
model.add(keras.layers.Dense(10, activation="softmax"))일단 출력층을 삽입.
(X_train_full, y_train_full), (X_test, y_test) = cifar10.load_data() X_train = X_train_full[5000:] y_train = y_train_full[5000:] X_valid = X_train_full[:5000] y_valid = y_train_full[:5000]학습률 튜닝: [1e-5, 3e-5, 1e-4, 3e-4, 1e-3, 3e-3, 1e-2] 이중에 accuracy와 학습곡선이 제일 나은걸 찾아볼 것

https://velog.io/@heezeo/%EB%B3%80%EC%88%98%EB%AA%85-%EC%A7%80%EC%A0%95%EC%9D%98-%EC%9E%90%EB%8F%99%ED%99%94%EA%B0%80-%ED%95%84%EC%9A%94%ED%95%A0-%EB%95%90-globals-%ED%95%A8%EC%88%98 for i,x in enumerate([1e-5, 3e-5, 1e-4, 3e-4, 1e-3, 3e-3, 1e-2]): globals()['model_{}'.format(i)]=model globals()['model_{}'.format(i)].compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Nadam(learning_rate=x), metrics=['accuracy']) history=globals()['model_{}'.format(i)].fit(X_train,y_train,epochs=10,validation_data=(X_valid, y_valid)) # Plotting acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] plt.figure(figsize=(8, 8)) plt.subplot(2, 1, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.ylabel('Accuracy') plt.ylim([min(plt.ylim()),0.5])#잘 안보여서 고침 plt.title('Training and Validation Accuracy_{}'.format(i)) plt.subplot(2, 1, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.ylabel('Cross Entropy') # plt.ylim([0,1.0]) plt.title('Training and Validation Loss_{}'.format(i)) plt.xlabel('epoch') plt.show()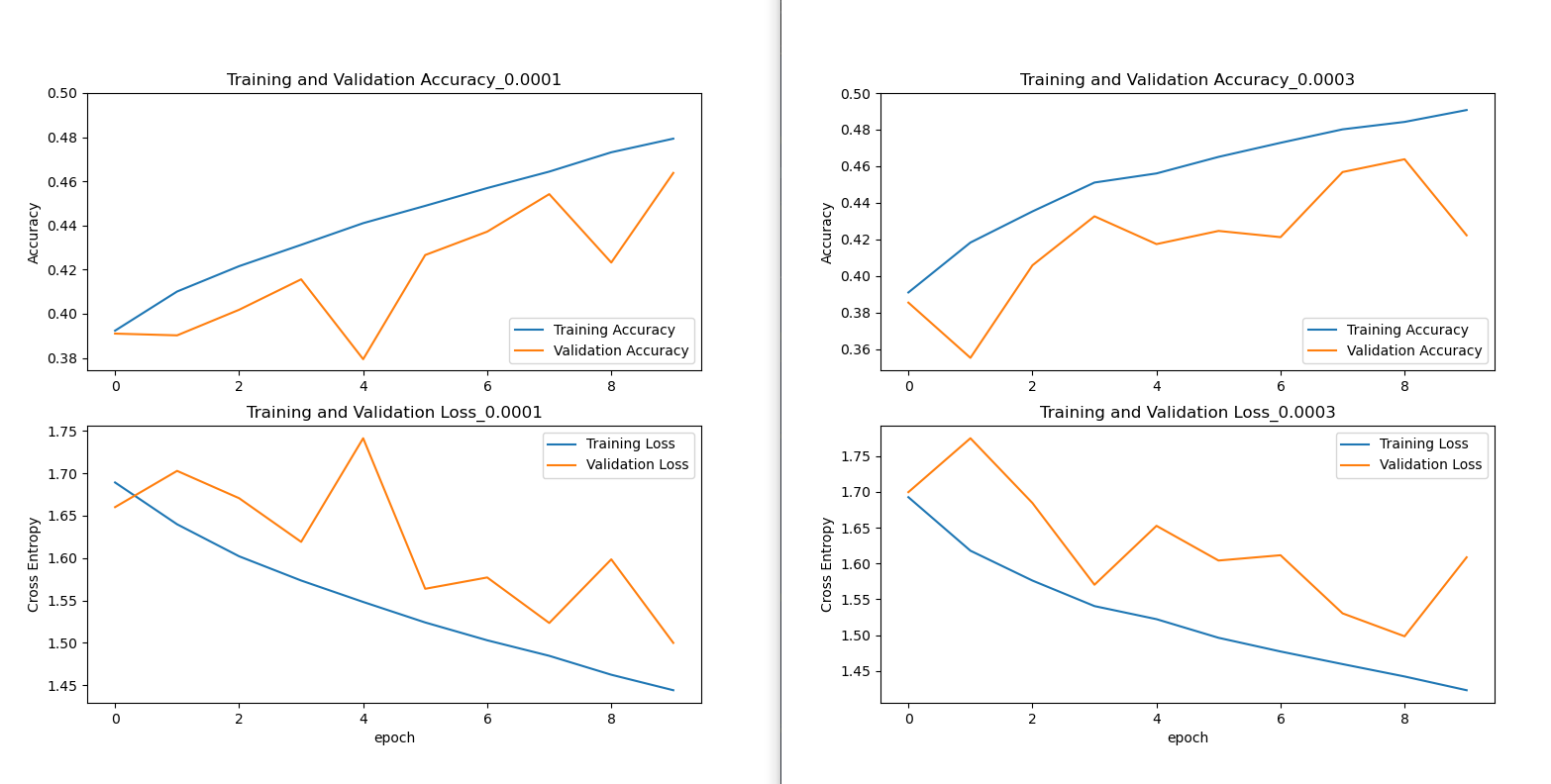
가장 나았던 학습곡선과 학습률 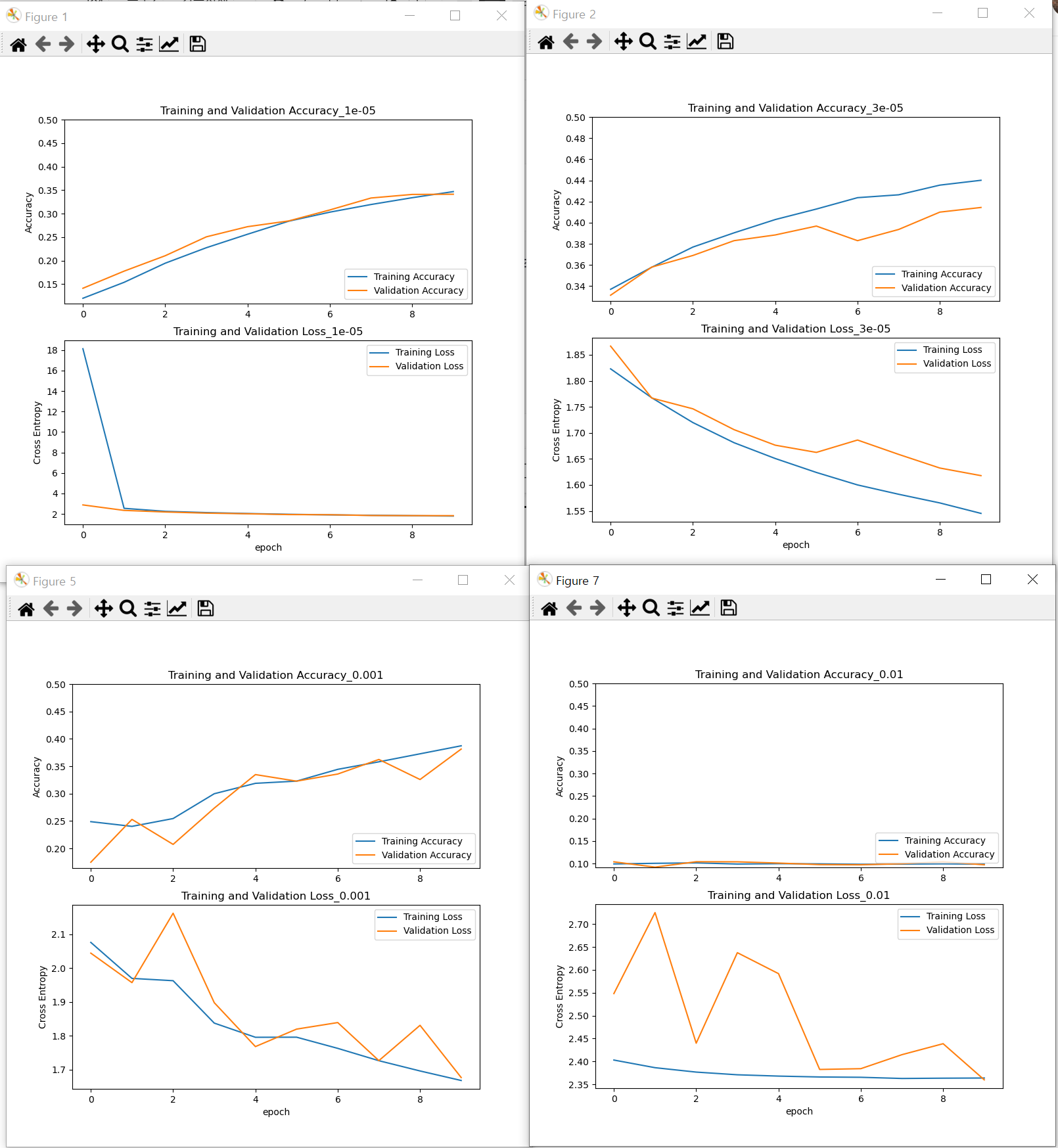
나머지.... 캡쳐실력 너무 허접하다 사실 주피터를 썼다면... 이렇지 않았겠지 0.0001~0.0003 정도에서 가장 좋은 정확도와 loss를 보이고 있는 것을 알 수 있다.
0.0003를 쓰도록 하자!
저 위에 코드는 답지랑 조금 다르다. 내가 이해되는 만큼만 쓰고 나머지는 구글링했다.
model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Nadam(learning_rate=0.0003), metrics=['accuracy']) checkpoint_cb=keras.callbacks.ModelCheckpoint( r"C어쩌구공부\model\my11modelb.h5", save_best_only=True) early_stopping_cb=keras.callbacks.EarlyStopping(patience=10,restore_best_weights=True) callbacks=[checkpoint_cb,early_stopping_cb] history=model.fit(X_train,y_train,epochs=100,validation_data=(X_valid, y_valid),callbacks=callbacks) model = keras.models.load_model( r"어쩌구\공부\model\my11modelb.h5") model.evaluate(X_valid, y_valid)157/157 [==============================] - 0s 1ms/step - loss: 2.3024 - accuracy: 0.1038
Out[186]: [2.302367687225342, 0.10379999876022339]아니 정확도 10%...? 무슨일이요.... 찍은거랑 다르지 않다.
답지랑 다른데 ㅠ 뭐가 잘못된거지? 일단 넘어가자....
#c.문제: 배치 정규화를 추가하고 학습 곡선을 비교해보세요.
# 이전보다 빠르게 수렴하나요? 더 좋은 모델이 만들어지나요? 훈련 속도에는 어떤 영향을 미치나요?배치 정규화 기법은 그라디언트 소실과 폭주 문제를 해결하기 위해 만들어짐.
매우매우 중요하다고 한다!
각 층에서 활성화 함수를 통과하기 전후에 연산을 하나 추가한다.
입력을 원점에 맞추고 정규화한 다음, (위치 파라미터와 스케일 파라미터로)각 층에서 결괏값의 스케일을 조정하고 이동시킴.
-
왜 쓰는 것일까? mnist 데이터를 예로 들어서, 데이터 안에 3들이 많이 있다.
하지만 그 중에는 3이라고 도저히 볼수 있는 3들도 있다.
그런 data에 똑같이 WX+b를 하면 굉장히 튀는 값이 될 것이다.
그러면 WX+b의 분포가 왜곡되게 된다. 이는 비선형함수를 거치면서 훨씬 더 효과가 증폭되게 된다.
이때 WX+b의 분포를 scaling 해서 정규분포 (0,1) 로 맞춰준다. 이러면 gradient가 좋아진다고 한다.
굉장히 중요한 개념이라고 한다!
-
장점으로는, 그라디언트 소실 문제가 크게 감소하고, 가중치 초기화에 네트워크가 훨씬 덜 민감해짐. 훨씬 큰 학습률을 이용하여 학습 과정의 속도를 크게 높일 수 있었음.
단점은, 모델의 복잡도를 키우며 실행 시간 면에서도 손해라는 점.
하지만 내가 해봤는데 정말 드라마틱하게 정확도가 올라간다...
modelc=keras.models.Sequential() modelc.add(keras.layers.Flatten(input_shape=[32,32,3])) modelc.add(keras.layers.BatchNormalization()) for _ in range(20): modelc.add(keras.layers.Dense(100, kernel_initializer="he_normal")) modelc.add(keras.layers.BatchNormalization()) modelc.add(keras.layers.Activation("elu")) modelc.add(keras.layers.Dense(10, activation="softmax")) modelc.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Nadam(learning_rate=0.0003), metrics=['accuracy']) checkpoint_cb=keras.callbacks.ModelCheckpoint( r"\공부\model\my11modelc.h5", save_best_only=True) early_stopping_cb=keras.callbacks.EarlyStopping(patience=10,restore_best_weights=True) callbacks=[checkpoint_cb,early_stopping_cb] history=modelc.fit(X_train,y_train,epochs=100,validation_data=(X_valid, y_valid),callbacks=callbacks) model = keras.models.load_model( r"\공부\model\my11modelc.h5") model.evaluate(X_valid, y_valid)Epoch 25/100
1407/1407 [==============================] - 12s 8ms/step - loss: 1.1238 - accuracy: 0.6030 - val_loss: 1.3626 - val_accuracy: 0.5248에포크 25에서 조기종료 되었다. 에포크당 시간은 더 늘어났지만, 훨씬 빨리 수렴했다.
정확도는 약 52%를 보여주고 있어서 매우매우!! 향상된 것을 알수 있다.
#d. 문제: 배치 정규화를 SELU로 바꾸어보세요. 네트워크가 자기 정규화하기 위해 필요한 변경 사항을 적용해보세요# (즉, 입력 특성 표준화, 르쿤 정규분포 초기화, 완전 연결 층만 순차적으로 쌓은 심층 신경망 등).
입력을 표준화하고, 르쿤 정규분포 초기화를 해주었다. 너무 힘들어서 르쿤 정규분포 초기화가 뭔지는 설명하지 않겠다. 나도 몰라... 사실 뭐 몰라도 된다고 한다. 적당히 이런게 있다고 알기만 하자.
keras.backend.clear_session() modeld=keras.models.Sequential() modeld.add(keras.layers.Flatten(input_shape=[32,32,3])) for _ in range(20): modeld.add(keras.layers.Dense(100, kernel_initializer="lecun_normal")) modeld.add(keras.layers.Activation("selu")) modeld.add(keras.layers.Dense(10, activation="softmax")) modeld.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Nadam(learning_rate=0.0003),#### metrics=['accuracy']) X_means = X_train.mean(axis=0) X_stds = X_train.std(axis=0) X_train_scaled = (X_train - X_means) / X_stds X_valid_scaled = (X_valid - X_means) / X_stds X_test_scaled = (X_test - X_means) / X_stds checkpoint_cb=keras.callbacks.ModelCheckpoint( r"\공부\model\my11modeld.h5", save_best_only=True) early_stopping_cb=keras.callbacks.EarlyStopping(patience=10,restore_best_weights=True) callbacks=[checkpoint_cb,early_stopping_cb] history=modeld.fit(X_train,y_train,epochs=100,validation_data=(X_valid, y_valid),callbacks=callbacks)47.9%의 정확도로, 빠르기는 에포크당 7초로 가장 빨리 걸렸다. 적당한 정확도에 가장 빠른 모델이다.
#e. 문제: 알파 드롭아웃으로 모델에 규제를 적용해보세요.(몬테카를로 드롭아웃은 그냥 내가 뺌)
드롭아웃은 심층 신경망에서 가장 인기있는, 과적합을 막기 위한 규제 기법중 하나라고 한다!
(근데 요즘 논문들에서는 잘 안쓴다는 이야기가 있다...어쨌든)
매우 간단한 방식이다.
매 훈련 스탭에서 입력 뉴런은 확률적으로 드롭아웃될 확률 p를 가진다(그냥 랜덤이라는 소리임)
즉 이번 훈련 스텝에서는 무시되지만 다음 스텝에서는 활성화 될 수 있다는 소리.
근데 이 드롭아웃에 대한 비판은, training 할때마다 껏다켰다 하는데 test할때는 얘를 안쓴다.
일관성이 있냐?하는 그런 이야기도 있다고 한다.
modele=keras.models.Sequential() modele.add(keras.layers.Flatten(input_shape=[32,32,3])) for _ in range(20): modele.add(keras.layers.Dense(100, kernel_initializer="lecun_normal")) modele.add(keras.layers.Activation("selu")) modele.add(keras.layers.AlphaDropout(rate=0.1)) #많은 신경망 구조는 마지막 은닉층 뒤에만 드롭아웃 지정 #드롭아웃을 전체에 적용하는 것이 너무 강하다면 이렇게 시도해보자, # 드롭아웃 비율 [0.05,0.1,0.2,0.4] 학습률 [1e-4, 3e-4, 5e-4, 1e-3] 그리드 서치 필요 modele.add(keras.layers.Dense(10, activation="softmax")) modele.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Nadam(learning_rate=3e-5),#### metrics=['accuracy']) X_means = X_train.mean(axis=0) X_stds = X_train.std(axis=0) X_train_scaled = (X_train - X_means) / X_stds X_valid_scaled = (X_valid - X_means) / X_stds X_test_scaled = (X_test - X_means) / X_stds checkpoint_cb=keras.callbacks.ModelCheckpoint( r"\공부\model\my11modele.h5", save_best_only=True) early_stopping_cb=keras.callbacks.EarlyStopping(patience=10,restore_best_weights=True) callbacks=[checkpoint_cb,early_stopping_cb] history=modele.fit(X_train,y_train,epochs=100,validation_data=(X_valid, y_valid), callbacks=callbacks)드롭아웃 비율과 학습률에 대한 그리드 서치가 필요한데 안했다.. 힘들고.. 귀찮고...
Epoch 31/100
1407/1407 [==============================] - 8s 6ms/step - loss: 1.2192 - accuracy: 0.5659 - val_loss: 1.5445 - val_accuracy: 0.4870f. 문제: 1사이클 스케줄링으로 모델을 다시 훈련하고 훈련 속도와 모델 정확도가 향상되는지 확인해보세요.
코드가 너무 어려워서 나중에 리뷰하도록 하겠다...
K = keras.backend class ExponentialLearningRate(keras.callbacks.Callback): def __init__(self, factor): self.factor = factor self.rates = [] self.losses = [] def on_batch_end(self, batch, logs): self.rates.append(K.get_value(self.model.optimizer.lr)) self.losses.append(logs["loss"]) K.set_value(self.model.optimizer.lr, self.model.optimizer.lr * self.factor) def find_learning_rate(model, X, y, epochs=1, batch_size=32, min_rate=10**-5, max_rate=10): init_weights = model.get_weights() iterations = math.ceil(len(X) / batch_size) * epochs factor = np.exp(np.log(max_rate / min_rate) / iterations) init_lr = K.get_value(model.optimizer.lr) K.set_value(model.optimizer.lr, min_rate) exp_lr = ExponentialLearningRate(factor) history = model.fit(X, y, epochs=epochs, batch_size=batch_size, callbacks=[exp_lr]) K.set_value(model.optimizer.lr, init_lr) model.set_weights(init_weights) return exp_lr.rates, exp_lr.losses def plot_lr_vs_loss(rates, losses): plt.plot(rates, losses) plt.gca().set_xscale('log') plt.hlines(min(losses), min(rates), max(rates)) plt.axis([min(rates), max(rates), min(losses), (losses[0] + min(losses)) / 2]) plt.xlabel("Learning rate") plt.ylabel("Loss") class OneCycleScheduler(keras.callbacks.Callback): def __init__(self, iterations, max_rate, start_rate=None, last_iterations=None, last_rate=None): self.iterations = iterations self.max_rate = max_rate self.start_rate = start_rate or max_rate / 10 self.last_iterations = last_iterations or iterations // 10 + 1 self.half_iteration = (iterations - self.last_iterations) // 2 self.last_rate = last_rate or self.start_rate / 1000 self.iteration = 0 def _interpolate(self, iter1, iter2, rate1, rate2): return ((rate2 - rate1) * (self.iteration - iter1) / (iter2 - iter1) + rate1) def on_batch_begin(self, batch, logs): if self.iteration < self.half_iteration: rate = self._interpolate(0, self.half_iteration, self.start_rate, self.max_rate) elif self.iteration < 2 * self.half_iteration: rate = self._interpolate(self.half_iteration, 2 * self.half_iteration, self.max_rate, self.start_rate) else: rate = self._interpolate(2 * self.half_iteration, self.iterations, self.start_rate, self.last_rate) self.iteration += 1 K.set_value(self.model.optimizer.lr, rate) batch_size = 128 rates, losses = find_learning_rate(model, X_train_scaled, y_train, epochs=1, batch_size=batch_size) plot_lr_vs_loss(rates, losses) plt.axis([min(rates), max(rates), min(losses), (losses[0] + min(losses)) / 1.4])keras.backend.clear_session() tf.random.set_seed(42) np.random.seed(42) model = keras.models.Sequential() model.add(keras.layers.Flatten(input_shape=[32, 32, 3])) for _ in range(20): model.add(keras.layers.Dense(100, kernel_initializer="lecun_normal", activation="selu")) model.add(keras.layers.AlphaDropout(rate=0.1)) model.add(keras.layers.Dense(10, activation="softmax")) optimizer = keras.optimizers.SGD(learning_rate=1e-3) model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])'[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리 3 (0) 2022.07.01 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리2 (0) 2022.07.01 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리1 (0) 2022.06.28 [HandsOn]12. 텐서플로를 사용한 사용자 정의 모델과 훈련 - 연습문제 (0) 2022.02.15 [HandsOn]10. 케라스를 사용한 인공 신경망- 연습문제 (0) 2022.01.12 - 시그모이드, 하이퍼볼릭 탄젠트는 입력값이 커질수록 그라디언트가 0에 가까워짐->