-
[HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리 3[도서완독]Hands On Machine Learning 2022. 7. 1. 21:42
10.2.4 함수형 API를 사용해 복잡한 모델 만들기
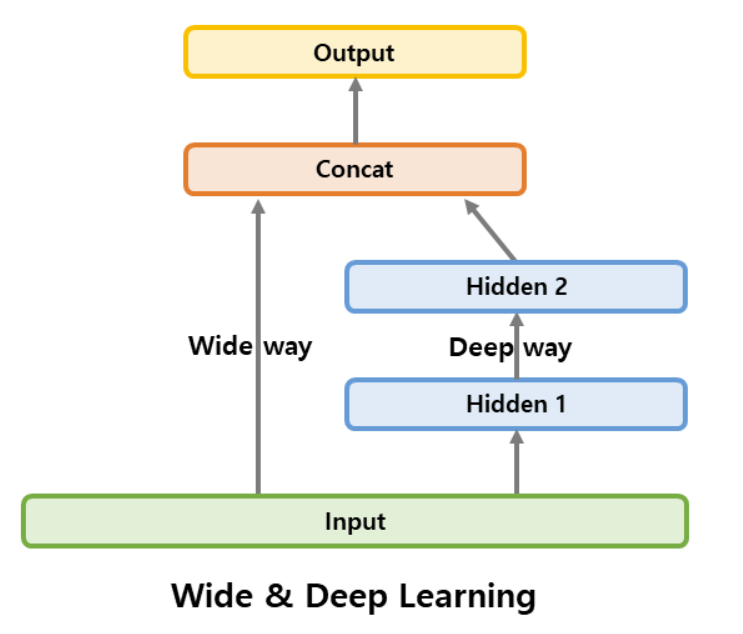
https://gooopy.tistory.com/100 순차적이지 않은 신경망의 예. 복잡한 패턴과 간단한 규칙을 모두 학습할 수 있다.
이런 신경망을 만들어서 캘리포니아 주택 문제를 해결해보자!
input_=keras.layers.Input(Shape=X_train.shape[1:]) hidden1=keras.layers.Dense(30,activation='relu')(input_) hidden2=keras.layers.Dense(30,activation='relu')(hidden1) concat=keras.layers.Concatenate()([input_,hidden2]) output=keras.layers.Dense(1)(concat) model=keras.Model(inputs=[input_],outputs=[output])요렇다. 이건 쉽게 이해 가능함.
일부 특성은 짧은 경로로, 다른 특성들은 깊은 경로로 전달하고 싶다면?
여러 입력을 사용!
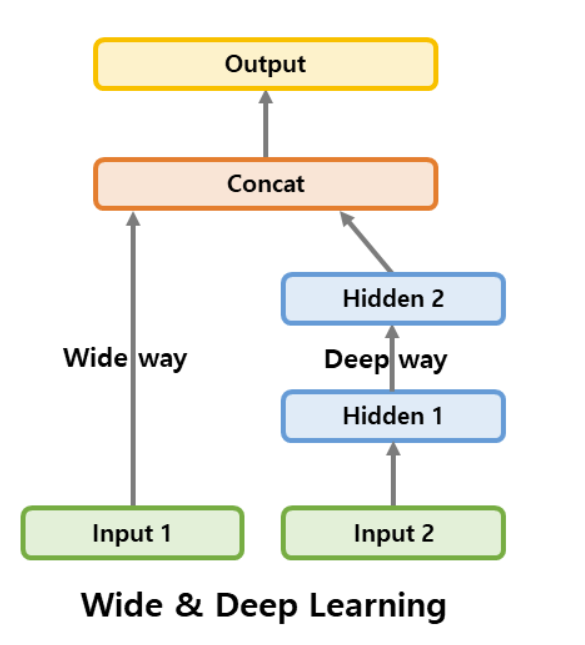
https://gooopy.tistory.com/103?category=876252 input_A=keras.layers.Input(shape=[5],name='wide_input') input_B=keras.layers.Input(shape=[6],name='deep_input') hidden1=keras.layers.Dense(30,activation='relu')(input_B) hidden2=keras.layers.Dense(30,activation='relu')(hidden1) concat=keras.layers.concatenate([input_A,hidden2]) output=keras.layers.Dense(1,name='output')(concat) model=keras.Model(inputs=[input_A,input_B],outputs=[output])컴파일할 때, 하나의 X_train을 전달하는 것이 아니라 입력마다 하나씩 행렬의 튜플 (X_train_A, X_train_B)를 전달해야 함.
X_valid에도 동일, X_test와 X_new에도 동일
여러개의 출력이 필요한 경우

https://gooopy.tistory.com/104?category=876252 - 적절한 층에 연결하고 모델의 출력 리스트에 추가
- 출력들의 손실에 가중치를 부여할 수 있음
10.2.5 서브클래싱 API를 사용해 동적 모델 만들기
어려워서 담에....
10.2.6 모델 저장과 복원
시퀀셜, 함수형 API의 경우 케라스 모델을 저장하는 것은 쉽다고 한다.
model.save("my_keras_model.h5")HDF5 포맷을 사용
모델 로드
model=keras.models.load_model("my_keras_model.h5")서브클래싱에서는 파라미터만 저장 , 복원 가능
그 외에는 모두 수동으로 저장하고 복원해야 함
훈련이 몇시간동안 지속되는 경우에, 컴퓨터에 문제가 생겨 모든 것을 잃어버린다면??
훈련 도중 일정 간격으로 체크포인트를 저장해야 함!!!
콜백(callback)을 사용
10.2.7 콜백 사용하기
[...]모델을 만들고 컴파일하기 early_stopping_cb=keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True) checkpoint_cb=keras.callbacks.ModelCheckpoint("my_keras_model.h5",save_best_only=True) history=model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid), callbacks=[checkpoint_cb,early_stopping_cb] model=keras.models.load_model("my_keras_model.h5")기본적으로 매 에포크의 끝에서 호출
save_best_only=True : 최상의 검증 세트 점수에서만 모델을 저장
EarlyStopping: 일정 에포크 동안 검증 세트에 대한 점수가 향상되지 않으면 훈련을 멈춤
체크포인트 저장 콜백과 훈련을 일찍 멈추는 콜백 함께 사용 가능
사용자 정의 콜백을 만들수도 있음!!
예를 들어, 훈련 동안 검증 손실과 훈련 손실의 비율을 출력(과대적합 감지)
class PrintValTrainRatioCallback(keras.callbacks.Callback): def on_epoch_end(self,epoch,logs): print("\nval/train : {:.2f}".format(logs["val_loss]/logs["loss"]))on_train_begin(), on_train_end(),... on_batch_begin() 등을 구현 가능
test, predict 에도 똑같이 사용 가능
10.2.8 텐서보드를 사용해 시각화하기
훈련하는 동안 학습 곡선을 그리거나, 여러 실행 간의 학습 곡선을 비교하고 계산 그래프 시각화, 훈련 통계 분석 수행 가능
텐서보드 로그를 위해 사용할 루트 로그 디렉터리를 정의
현재 날짜와 시간을 사용해 실행할 때마다 다른 서브디렉터리 경로를 생성하는 함수 만듬
테스트 파라미터 값 같은 정보를 로그 디렉터리 이름으로 사용 가능
import os root_logdir = os.path.join(os.curdir,"my_logs") #현재 디렉토리/my_logs 를 루트 로그 디렉토리로 정의 def get_run_logdir(): import time run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")#time을 다음과 같은 문자열로 변환 return os.path.join(root_logdir,run_id) #루트 디렉토리 밑의 주소 생성 run_logdir=get_run_logdir()tensorboard_cb=keras.callbacks.TensorBoard(run_logdir) history=model.fit(X_train,y_train,epochs=30,validation_data=(X_valid, y_valid), callbacks=[tensorboard_cb])이 코드를 실행하면 콜백이 로그 디렉터리를 생성하고, 훈련하는 동안 이벤트 파일을 만들고 서머리 기록.
파라미터 튜닝 후 두번째 실행하면 또 디렉터리가 생성됨

이런식으로 디렉토리 밑에 로그 파일이 생김 텐서보드 서버를 시작해보자.

터미널 명령을 실행(가상환경 활성화, 로그 디렉터리의 상위 디렉터리에서 명령 실행) 서버가 실행되면 웹 브라우저를 열고 http://localhost:6006 으로 접속
근데 안됨... wandb라는걸 쓰도록 하자.
요즘 텐서보드 아무도 안쓴다고 함(서울시립대 박사과정 피셜. 반박시 전화 가능하다고 함..)

10.3 신경망 하이퍼파라미터 튜닝하기
층의 개수, 뉴런 개수, 활성화 함수, 가중치 초기화 전략...
어떤 하이퍼파라미터 조합이 주어진 문제에 최적인지 어떻게 아는가?
한 가지 방법은 많은 조합을 시도해보고 어떤 것이 검증 세트에서 가장 좋은 점수를 내는지 확인하는 것.
GredSearchCV나 RandomizedSearchCV를 사용해 탐색 가능한데, 이렇게 하려면 케라스 모델을 사이킷런 추정기처럼 보이도록 바꾸어야 함.
이 방법은 잘 안쓴다고 함. wandb에서 스윕?? 기능을 사용하면 자동으로 랜덤/그리드 서치를 수행한다고 함.
대신 wandb에서는 내가 직접 최상의 파라미터 조합을 봐야 하는데, 래핑해서 객체를 만들면 최상의 파라미터와 모델을 던져주는거 같음.
은닉층 개수, 뉴런 개수, 학습률, 배치 크기, 옵티마이저
학습률이 가장 중요한 하이퍼파라미터임
옵티마이저는 adam
활성화함수는 웬만하면 relu
반복 횟수는 튜닝할 필요 없이 조기 종료
'[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn]11. 심층 신경망 훈련하기 - 내용 정리 2 (0) 2022.07.06 [HandsOn]11. 심층 신경망 훈련하기 - 내용 정리 1 (0) 2022.07.05 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리2 (0) 2022.07.01 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리1 (0) 2022.06.28 [HandsOn]12. 텐서플로를 사용한 사용자 정의 모델과 훈련 - 연습문제 (0) 2022.02.15