-
[HandsOn]11. 심층 신경망 훈련하기 - 내용 정리 1[도서완독]Hands On Machine Learning 2022. 7. 5. 15:51
10장에서 얕은 네트워크를 훈련해 보았다.
아주 복잡한 문제를 다뤄야 한다면?
아마도 수백 개의 뉴런으로 구성된 10개 이상의 층을 수십만 개의 가중치로 연결해 훨씬 더 깊은 신경망을 훈련해야 할 것...
훈련중 마주칠 수 있는 문제:
- 그레이디언트 소실 또는 그레이디언트 폭주 문제
- 대규모 신경망을 위한 훈련 데이터가 충분하지 않거나, 레이블을 만드는 작업에 비용이 너무 많이 들어갈 수 있음
- 훈련이 너무 느려짐
- 수백만 개의 파라미터를 가진 모델이 훈련 세트에 과대적합될 위험이 매우 큼.
특히 훈련 샘플이 충분하지 않거나 잡음이 많은 경우 그럼
그레이디언트 소실과 그레이디언트 폭주 문제의 널리 알려진 해결 방법
레이블 된 데이터가 적을 때 도움이 되는 전이 학습과 비지도 사전훈련
대규모 모델의 훈련 속도를 높여주는 다양한 최적화 방법
대규모 신경망을 위한 규제 기법 중 널리 알려진 몇 가지 사용11.1 그레이디언트 소실과 폭주 문제
그레이디언트 소실: 역전파 알고리즘에서 출력->입력층으로 오차 그레이디언트를 계산하여 파라미터를 수정하는데,
하위층으로 진행될수록 그레이디언트가 점점 작아짐-> 하위층의 가중치(파라미터)가 변경되지 않음-> 좋은 솔루션으로 수렴 되지 않음...
그레이디언트 폭주: 그레이디언트가 점점 커져서 여러 층이 비정상적으로 큰 가중치로 갱신-> 알고리즘 발산...
- 그래디언트 소실의 예:
sigmoid 활성화 함수 사용 시, 입력의 절대값이 커지면 함수값이 0,1로 수렴하는데, 이때 기울기가 0에 매우 가까워짐. - 최상위층부터 역전파가 될 때 사실상 신경망으로 전파할 그레이디언트가 거의 없고 .. 실제로 아래층에는 아무것도 도달하지 않게 됨.
11.1.1 글로럿과 He 초기화
이런 그레이디언트 문제를 크게 완화하는 방법 제안.
- 각 층의 출력에 대한 분산이 입력에 대한 분산과 같아야 한다는 주장!
층의 입력 연결 개수/ 출력 연결 개수: fan_in, fan_out
각 층의 연결 가중치를 다음과 같이 무작위로 초기화하는 것

글로럿 초기화: https://wikidocs.net/61271 - 르쿤, He 초기화
케라스는 기본적으로 균등분포의 글로럿 초기화를 사용.
층을 만들때 kernel_initializer="he_uniform"이나 kernel_initializer="he_normal"로 바꾸어 He 초기화 사용 가능
keras.layers.Dense(10,acrtivation="relu",kernel_initializer="he_normal")fan_in 대신 fan_out 기반의 균등븐포 He 초기화를 사용하고 싶다면 Variance Scaling을 사용 가능
he_avg_init=keras.initializers.VarianceScaling(scale=2.,mode='fan_avg',distribution='uniform') keras.layers.Dense(10,activation='sigmoid',kernel_initializer=he_avg_init)11.1.2 수렴하지 않는 활성화 함수
활성화 함수를 잘못 선택하면 그레이디언트의 소실이나 폭주로 이어질 수 있다!
Relu에서 나타나는 문제: 죽은 Relu (훈련하는 동안 일부 뉴런이 0 이외의 값을 출력하지 않는다는 의미)
모든 샘플에 대해 입력의 가중치 합이 음수가 됨-> Relu 함수의 그레이디언트가 0이 되므로 경사 하강법이 작동 x
LeakyReLU

작은 기울기가 있어서, 뉴런이 죽지 않음 (Relu보다 항상 성능이 높다)
ELU
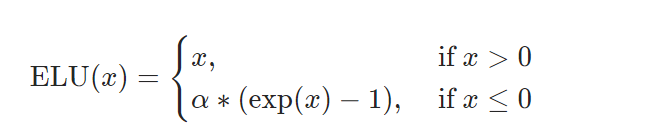

다른 모든 Relu변종의 성능을 앞지른다고 함. 훈련 시간이 줄고 신경망 테스트 세트 성능도 더 높았음.
but 계산이 느리다...
속도가 중요하다면 Relu가 가장 좋은 선택임.(모든 라이브러리들이 Relu에 특화되어 최적화되어 있음)
✨배치 정규화(batch normalization)✨ 매우 중요!
참고쓰
https://gaussian37.github.io/dl-concept-batchnorm/
배치 정규화(Batch Normalization)
gaussian37's blog
gaussian37.github.io
👩🦰 왜 배치 정규화가 필요할까?
Internal Covariant Shift
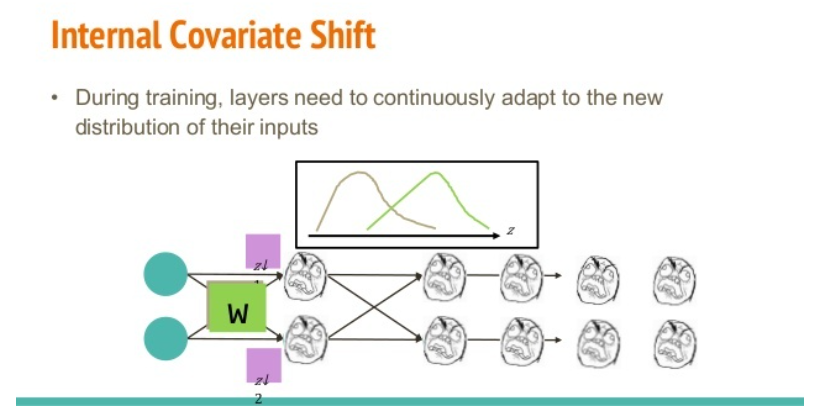
출처 : https://www.slideshare.net/ssuser950871/why-batch-normalization-works-so-well 학습의 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상!
혹은 배치 단위로 학습을 할 때 배치 단위간에 데이터 분포의 차이가 발생!
배치 사이의 분포가 다르니까 weight가 자꾸 바뀌고 부정확해짐....
이 문제를 개선하기 위한 개념이 Batch Normalization
- 각 층에서 활성화 함수를 통과하기 전이나 후에 모델에 연산을 하나 추가
- 입력을 원점에 맞추고 정규화-> 스케일 조정, 이동 파라미터로 결괏값의 스케일 변경
- 신경망의 첫 층으로 배치 정규화 추가하면 훈련 세트를 표준화할 필요가 없다.
1. 미니배치에 대해 평균, 표준편차를 구하고, 샘플i를 정규화한다.
2. z = r x 정규화된 샘플 i + b (입력의 스케일을 조정하고 이동함)- 그레이디언트 소실 문제가 크게 감소, 가중치 초기화에 네트워크가 훨씬 덜 민감해짐
- 모델의 복잡도를 키우고, 실행 시간 면에서도 손해
📌 학습 과정과 추론 과정의 알고리즘이 다름
- 훈련하는 동안 배치 통계를 사용하고 훈련이 끝난 후에는 최종 통계를 사용함(이동 평균의 마지막 값)
- 테스트 시에는 배치의 평균/분산 1...B를 이동하여 평균한 값 각각 1개(fix)를 평균과 분산으로 쓰게 됨.

https://gaussian37.github.io/dl-concept-batchnorm/ 케라스로 배치 정규화 구현
은닉층의 활성화 함수 전이나 후에 BatchNormalization 층을 추가하면 됨!
모델의 첫 층으로 배치 정규화 층을 추가할 수도 있음.
model=keras.models.Sequential([ keras.layers.Flatten(input_shape=[28,28]), keras.layers.BatchNormalization(), keras.layers.Dense(300,activation='elu',kernel_initializer="he_normal"), keras.layers.BatchNormalization(), keras.layers.Dense(100,activation='elu',kernel_initializer="he_normal"), keras.layers.BatchNormalization(), kerys.layers.Dense(10,activation='softmax') ])첫 층을 살펴보자.
[(var.name,var.trainable) for var in model.layers[1].variables]
활성화 함수 전에 배치 정규화 층을 추가하려면 은닉층에서 활성화 함수를 지정하지 말고 배치 정규화 층 뒤에 별도의 층으로 추가해야 한다. 또한 배치 정규화 층은 입력마다 이동 파라미터를 포함하기 때문에 이전 층에서 편향을 뺄 수 있다.
(무슨 소리인지 모르겠음... 저 위에 코드도 활성화 함수 전에 배치 정규화 층을 추가했는데?)
model=keras.models.Sequential([ keras.layers.Flatten(input_shape=[28,28]), keras.layers.BatchNormalization(), keras.layers.Dense(300,kernel_initializer="he_normal",use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("elu"), keras.layers.Dense(100,kernel_initializer="he_normal",use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("elu"), keras.layers.Dense(10,activation="softmax") ])- 하이퍼파라미터:
1. momentum
2. axis
11.1.4 그레이디언트 클리핑
그레이디언트 폭주를 완화하려면, 역전파될 때 일정 임곗값을 넘어서지 못하게 그레이디언트를 잘라내는 것
RNN같은 경우 배치 정규화를 적용하기 어려워서 이 방법을 많이 사용(다른 네트워크는 배치 정규화로 충분...)
케라스에서 그레이디언트 클리핑을 구현: clipvalue와 clipnorm 매개변수를 지정
optimizer=keras.optimizers.SGD(clipvalue=1.0) model.compile(loss="mse",optimizer=optimizer)'[도서완독]Hands On Machine Learning' 카테고리의 다른 글
[HandsOn]11. 심층 신경망 훈련하기 - 내용 정리 3 (0) 2022.07.08 [HandsOn]11. 심층 신경망 훈련하기 - 내용 정리 2 (0) 2022.07.06 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리 3 (0) 2022.07.01 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리2 (0) 2022.07.01 [HandsOn]10. 케라스를 사용한 인공 신경망 - 내용 정리1 (0) 2022.06.28